
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- RAM
- 오라클 버림 함수
- heap
- 오라클 trunc()
- netstat
- 이진탐색트리
- trunc(sysdate)
- 스레드
- ssd
- web
- MAP
- git push
- 스케줄 삭제
- trunc()
- 프로세스 종료
- queue
- ArrayList
- stack
- maven
- HDD
- 멀티스레드
- 정렬
- url
- HashMap
- desc
- trunc(date)
- Git
- cpu
- null
- Servlet
- Today
- Total
無테고리 인생살이
[Algorithm] 시간복잡도와 빅오표기법 본문
- 알고리즘이란
- 시간복잡도와 공간복잡도
- 빅오표기법
- 시간복잡도 줄이는 법
알고리즘이란?
: 어떤 목적을 달성하거나 결과물을 만들어내기 위해 거쳐야 하는 일련의 과정들
하나의 상황에서 다양한 알고리즘을 적용할 수 있다.
중요한 것은 '시간복잡도가 가장 낮은 알고리즘을 선택하는 것'이다.
시간 복잡도란?
: 특정 알고리즘을 수행하는데 걸리는 시간
시간 복잡도는 실제 시간을 측정해서 표현하는 것인가?
: NO
동일한 알고리즘이라도 컴퓨터 하드웨어나 프로그래밍 언어에 따라 실행시간이 크게 달라질 수 있기 때문에, 실제시간을 측정해서 시간복잡도를 나타내는 것은 객관적 지표가 될 수 없다.
그렇기에, 알고리즘에 사용되는 연산을 수치화해서 시간복잡도를 나타낸다.
공간 복잡도란?
: 알고리즘 수행에 사용되는 메모리 양
시간 복잡도와 공간 복잡도는 반비례적 경향(trade-off 관계)이 있고,
컴퓨터 성능의 발달로 인해 메모리 공간이 넘쳐나서 공간 복잡도에 대한 중요도는 떨어졌다고 한다.
알고리즘은 공간 복잡도보다 시간 복잡도를 줄이는 것이 핵심!
[개발용어] 트레이드오프(trade-off)란?
트레이드오프(trade-off)의 사전적 의미는 상충관계. 즉, 하나를 얻으면 다른 하나를 잃을 수 있는 관계를 말한다. 예시) 파일 압축을 많이할수록, 즉 데이터 크기를 줄일수록 화질저하 프로그램 성
chunsubyeong.tistory.com
알고리즘 성능 표기법
알고리즘의 실행시간을 책정하는데 중요하지 않는 상수와 계수들을 제거하고 가장 큰 영향을 주는 항만 계산하면,
알고리즘의 실행시간에서 중요한 성장률에 집중할 수 있는데 이것을 점근적 표기법(Asymptotic notation)이라 부른다.
점근적 표기법은 다음 세가지가 있다.
- 최상의 경우 : 빅 오메가 표기법 (Big-Ω Notation)
- 평균의 경우 : 빅 세타 표기법 (Big-θ Notation)
- 최악의 경우 : 빅 오 표기법 (Big-O Notation)
시간 복잡도와 공간 복잡도는 주로 빅오 표기법을 이용하여 나타낸다.
알고리즘이 최악일 경우를 판단하면, 평균과 가까운 성능으로 예측하기 쉽기 때문에 빅오표기법을 사용한다.
빅-오 표기법
시간 복잡도에는 여러 개념이 있지만 그중에서 ‘아무리 많이 걸려도 이 시간 안에는 끝날 것‘의 개념이 제일 중요하다.
예를 들어 동전을 튕겨서 뒷면이 나올 확률을 이야기해 본다면, 운이 좋으면 한 번에 뒷면이 나올 수도 있고 운이 좋지 않으면 3,4번 만에 뒷면이 나올수도 있다. 운이 나쁜 경우 n번 만큼 동전을 튕겨야 하는 최악의 경우가 발생하는데,
이 최악의 경우를 계산하는 방식을 '빅-오(Big-O) 표기법'이라고 부르며 이 방식을 가장 많이 사용한다.


※ 여기서 n이란 입력되는 데이터를 의미합니다.
O(1) - 상수 시간 (Constant time)
입력 데이터의 크기에 상관없이 언제나 일정한 시간이 걸리는 알고리즘
데이터가 얼마나 증가하든 성능에 영향을 거의 미치지 않는다.
1step으로 해당 value에 바로 접근 가능한 경우
ex) 해시충돌 없는 HashMap의 put, get, remove Method
O(log n) - 로그 시간 (Logarithmic time)
입력 데이터의 크기가 커질수록 처리 시간이 로그만큼 짧아지는 알고리즘
데이터가 10배가 되면, 처리 시간은 2배가 됩니다.
데이터가 2배가 되었지만, 1step++
ex) 이진 탐색, 순기능의 재귀
O(n) - 선형 시간 (Linear time)
입력 데이터의 크기에 비례해 처리 시간이 증가하는 알고리즘
데이터가 10배가 되면, 처리 시간도 10배가 됩니다.
ex) 1차원 for문
O(n log n) (Linear-Logarithmic)
데이터가 많아질수록 처리시간이 로그 배만큼 더 늘어나는 알고리즘
데이터가 10배가 되면, 처리 시간은 약 20배가 된다.
ex) 병합 정렬, 퀵 정렬
O(n²) - 2차 시간 (Quadratic time)
데이터가 많아질수록 처리시간이 급수적으로 늘어나는 알고리즘
데이터가 10배가 되면, 처리 시간은 최대 100배가 됩니다.
ex) 이중 루프
O(2ⁿ) - 지수 시간(Exponential time)
데이터량이 많아질수록 처리시간이 기하급수적으로 늘어나는 알고리즘
ex) 피보나치 수열, 역기능의 재귀
시간복잡도 줄이는 법
1. 반복문 줄이기
시간 복잡도에서 반복문이 시간 소모에 가장 큰 영향을 끼친다!
2. 적절한 자료구조 사용

3. 적절한 알고리즘 사용
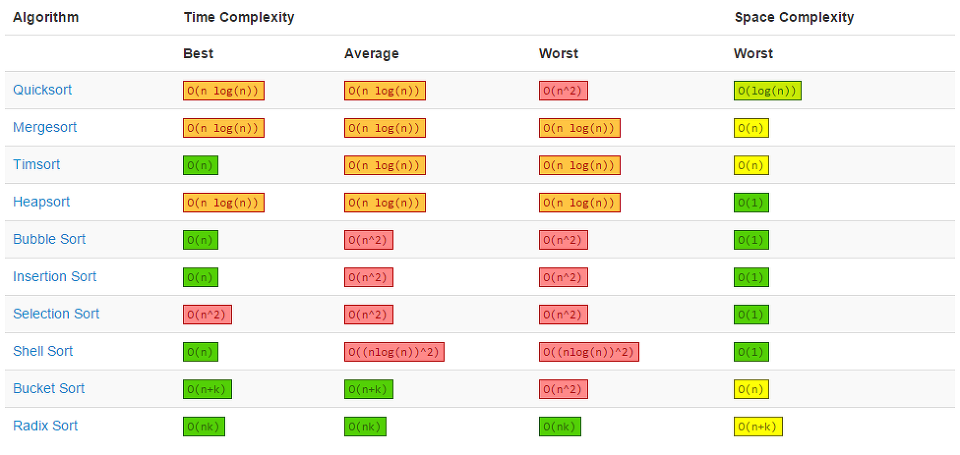
참고: https://blog.chulgil.me/algorithm/, https://coding-factory.tistory.com/608
'기타' 카테고리의 다른 글
| [개발용어] Load Factor, Threshold란? (0) | 2022.12.27 |
|---|---|
| [개발용어] boiler-plate code란? (0) | 2022.12.20 |
| [개발용어] Memory Leak이란? (0) | 2022.12.15 |
| [아키텍처] MSA 등장배경을 이해하고, 모놀리식 아키텍처와 장단점 비교해보자 (0) | 2022.11.08 |
| [개발용어] 트러블 슈팅이란? (0) | 2022.11.07 |
